
L’informatique ne cesse d’évoluer de jour en jour et le domaine de la virtualisation n’y échappe donc pas. Ce dernier a subi une grande évolution notamment grâce à l’arrivée de la virtualisation légère et la conteneurisation qui permet de gagner en agilité et en performance.
Les conteneurs prennent peu à peu la place d’une partie de la virtualisation traditionnelle. Il est donc important de savoir gérer les données de ces derniers et cela passe par leur sauvegarde.
En quoi les systèmes de sauvegarde actuels ne sont-ils pas adaptés aux conteneurs ?
Actuellement, les solutions de sauvegardes de machines virtuelles sont disponibles par milliers sur le marché et sont pour la plupart très efficaces mais malheureusement pas adaptées pour les conteneurs.
En effet, les solutions de sauvegardes actuelles fonctionnent de manière à sauvegarder soit des images de VM soit des snapshot directement.
Malheureusement (ou heureusement) Docker est totalement différent d’une machine virtuelle, c’est simplement une image, mais par défaut il n’a pas de volumes et les données ne sont donc pas persistantes dans l’image directement.
Mais alors que faut-il sauvegarder et comment ?
Cahier des charges pour sauvegarder un conteneur
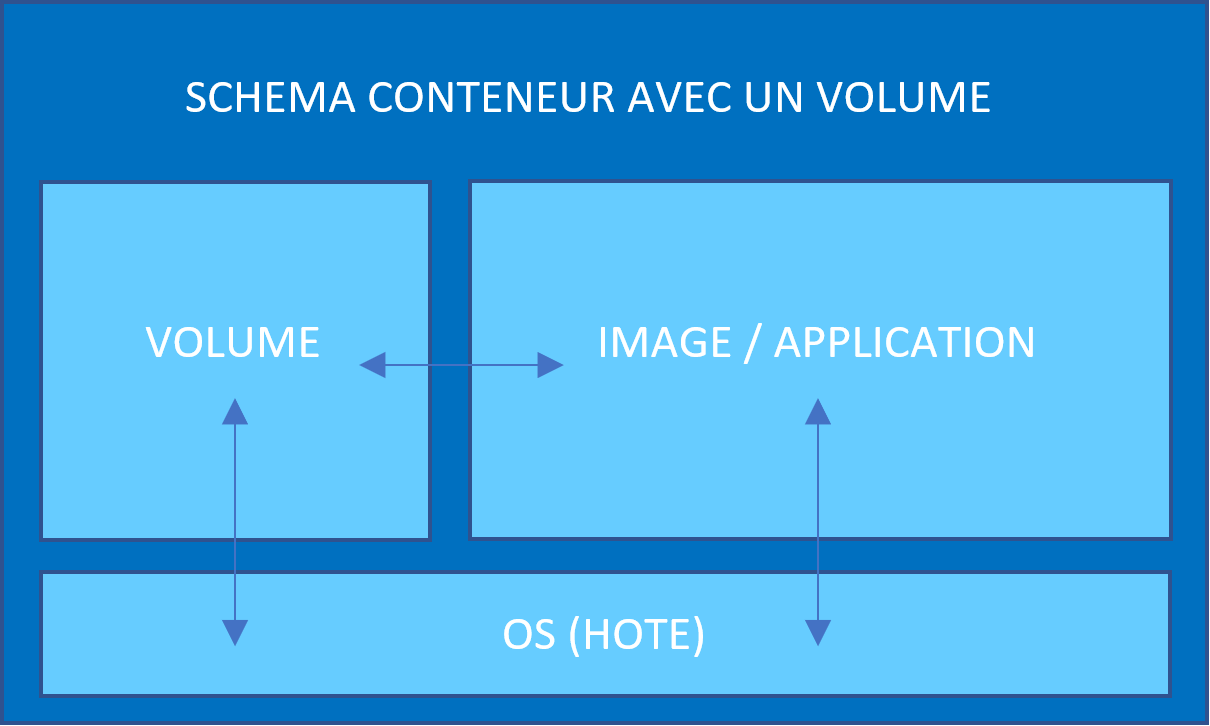
Définissons maintenant ce dont nous allons sauvegarder de notre conteneur. Pour nous aider à faire notre choix, voici une architecture basique d’un conteneur :
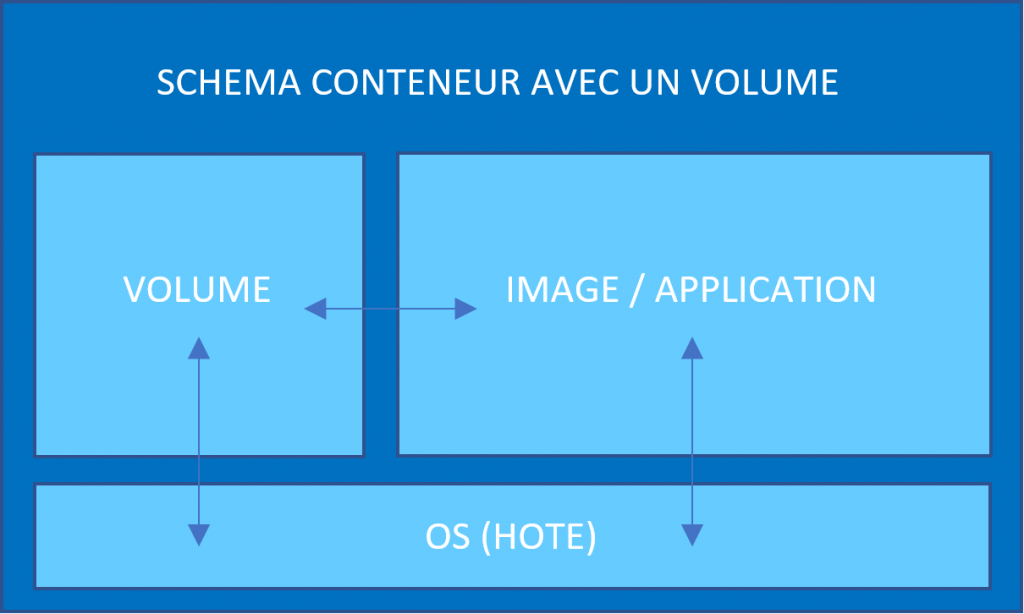
Nous pourrions sauvegarder le conteneur en lui-même ? Cette solution peut être envisagée mais nous n’avons pas besoin de tout cela pour restaurer un conteneur qui ne fonctionnerait plus, cela prendrait donc de la place de stockage inutilement.
La configuration ? Cette dernière est juste un simple fichier, il suffit de le copier sur un autre support pour ne pas la perdre, de plus une configuration peut toujours être à nouveau créée avec les mêmes caractéristiques (De nombreux exemples sont disponibles sur Docker HUB).
Les données ? C’est sûrement la partie la plus sensible du conteneur et celle dont nous allons vouloir sauvegarder le contenu.
Notre but est donc de sauvegarder cette partie et pourquoi pas, la répliquer sur d’autres supports.
Quelles solutions ou processus à mettre en place pour atteindre notre but ?
Nous allons mettre en place un mode opératoire permettant la sauvegarde des données de notre conteneur. Pour ce faire, nous allons nous appuyer sur les volumes docker (https://docs.docker.com/storage/volumes/).
Tout d’abord créez un volume, si vous utilisez Docker en CLI, utilisez la commande suivante :
# docker volume create volume-testPour s’assurer que le volume soit présent et pour lister les autres :
# docker volume lsPar ailleurs, si vous souhaitez obtenir plus de détails sur un volume, la commande est la suivante :
# docker volume inspect volume-testIl ne vous reste plus qu’à démarrer votre docker en liant le volume « volume-test ».
- En utilisant « -v » par exemple pour nginx :
# docker run -d --name=nginxtest -v volume-test:/usr/share/nginx/html nginx:latestMaintenant que les données de votre docker sont situées dans un volume, à vous de choisir la solution la plus adaptée pour répliquer ou sauvegarder ces derniers. Cependant voici quelques pistes de réflexions :
- Script crontab pour copier une archive de données (tar -xvf)
https://www.linuxtricks.fr/wiki/cron-et-crontab-le-planificateur-de-taches
- Duplicati (qui peut lui aussi, être lancé dans un Docker)
https://homputersecurity.com/2017/12/15/comment-realiser-vos-backups-personnels-avec-duplicati/
En pratique
Dans le cadre de cet article nous allons utiliser la solution de scripting crontab qui permet d’effectuer des tâches récurrentes sur un serveur Linux.
Pour installer cet utilitaire sur votre hôte (l’OS) il suffit de faire la commande (Debian) apt install cron, (CentOS & RedHat) yum install cronie.
Voici la syntaxe à respecter d’un crontab :
# Example of job definition:# .---------------- minute (0 - 59)# | .------------- hour (0 - 23)# | | .---------- day of month (1 - 31)# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat# | | | | |# * * * * * user command to be executed
Par exemple, afin d’exécuter un script tous les jours à 22h, il faudra utiliser cette commande :
# 00 22 * * * /root/scripts/sauvegarde.sh >> sauvegarde.log
Voici un exemple de script permettant la sauvegarde d’un dossier :
#!/bin/bash
# Quels répertoires sauvegarder ?
backup_files="/chemin/de/votre/volume"
# Destination de la sauvegarde.
dest="/mnt/sauvegarde"
# Création du nom de l’archive.
day=$(date +%A)
hostname=$(hostname -s)
archive_file="$hostname-$day.tgz"
# Affichage de l’état de la sauvegarde en cours
echo "Sauvegarde de $backup_files vers $dest/$archive_file"
date
echo
# Sauvegarde des fichiers dans $dest/$archive_file
tar czf $dest/$archive_file $backup_files
# Message de fin
echo
echo "Sauvegarde terminée"
date
Vous avez maintenant tous les outils techniques nécessaires à la bonne sauvegarde de vos volumes et donc des données de vos conteneurs.
Maintenant, il nous reste deux questions essentielles afin d’avoir un système de sauvegarde performant : à quelle fréquence dois-je sauvegarder mes volumes ? Comment tester mes restaurations ?
Pour la première question, tout dépend de l’importance que vous accordez à vos données. Ce qu’il faut se demander c’est, combien d’heures ou jours de données êtes vous prêt à perdre au maximum ? Vous aurez alors la fréquence de sauvegarde à mettre en place, il suffit donc d’adapter la commande crontab à la fréquence souhaitée.
Pour la restauration, la procédure est simple il suffit d’extraire l’archive dans le volume concerné.
# tar -xvzf /chemin/vers/archive -C /chemin/vers/volume de test restau/Vous l’aurez compris, nous choisissons d’extraire l’archive dans un volume de test (que l’on aura lié précédemment au conteneur). Une fois l’archive décompressé dans le volume, vérifiez dans l’application que le conteneur exécute, si les données s’y trouvent bien.
Pour rappel : un système de sauvegarde est jugé fonctionnel uniquement lorsqu’il est testé de bout à bout en condition réelle !
En conclusion
Nous avons pu voir que même avec la virtualisation dite légère, il est possible de sauvegarder ses données. Avec tous ce procédé de sauvegarde en place, nous pourrions imaginer formaliser le processus afin de s’approcher d’une gestion complète du cycle de vie d’une instance applicative, avec un environnement de développement, de test, de préproduction et de production.


